
Network Redundancy
Network redundancy
When we think and talk about network redundancy, the discussion normally stops at the internet connection. The true workhorse of business connectivity lies in the internal network, it’s just as critical as the edge. The switches, access points, uplinks, and structured cabling that silently do the bulk of the heavy lifting can quickly become single points of failure if not designed with resilience or redundancy in mind.
It’s all well and good having lightning-fast internet with failover, powerful cloud or on prem servers, and best-in-class end-user devices, if this all hinges on a single switch, poor network topology (this can happen organically as the network grows) or uplinks between infrastructure, we are introducing risk and playing high stakes gambling with uptime and continuity.
Once again, a logical network diagram is my best friend in this situation, it should be yours too. I find myself coming back to it time and time again even in the smallest of networks with one or two switches.
Networks and building cost effective redundancies for business’s
Now that we have tackled the edge, we can open the cabinet door and get tangled in patch leads, switches and structured cabling.
The humble network switch often overlooked, forgotten possibly covered in-dust, is the reliable workhorse of every business. These devices often sit in all manner of locations for all sizes of businesses work day after day, week after week, month after month and year after year without skipping a beat.
How do we ensure should a switch fail we can either be unaffected by this or at the very least minimise the amount of downtime caused?
This is not an easy question to answer often it will make people wince. Let’s break it down into sections and what we can do both from a physical aspect and a technological standpoint, where we can build redundancy in a cost effective manner without compromising, and (spoiler) where we have to concede to physical limitations if it is for a large network spanning across a campus, or a single rented office in a tenanted building.
Core
Building a resilient core is no easy feat. From a physical hardware point of view, we can implement multiple core switches to create diverse paths to the edge routers and distribution layers. Where possible utilising dual power supplies, fed from different sources adding further protection to these critical devices.
Now we can focus on the technologies we can employ to develop redundancy at this level.
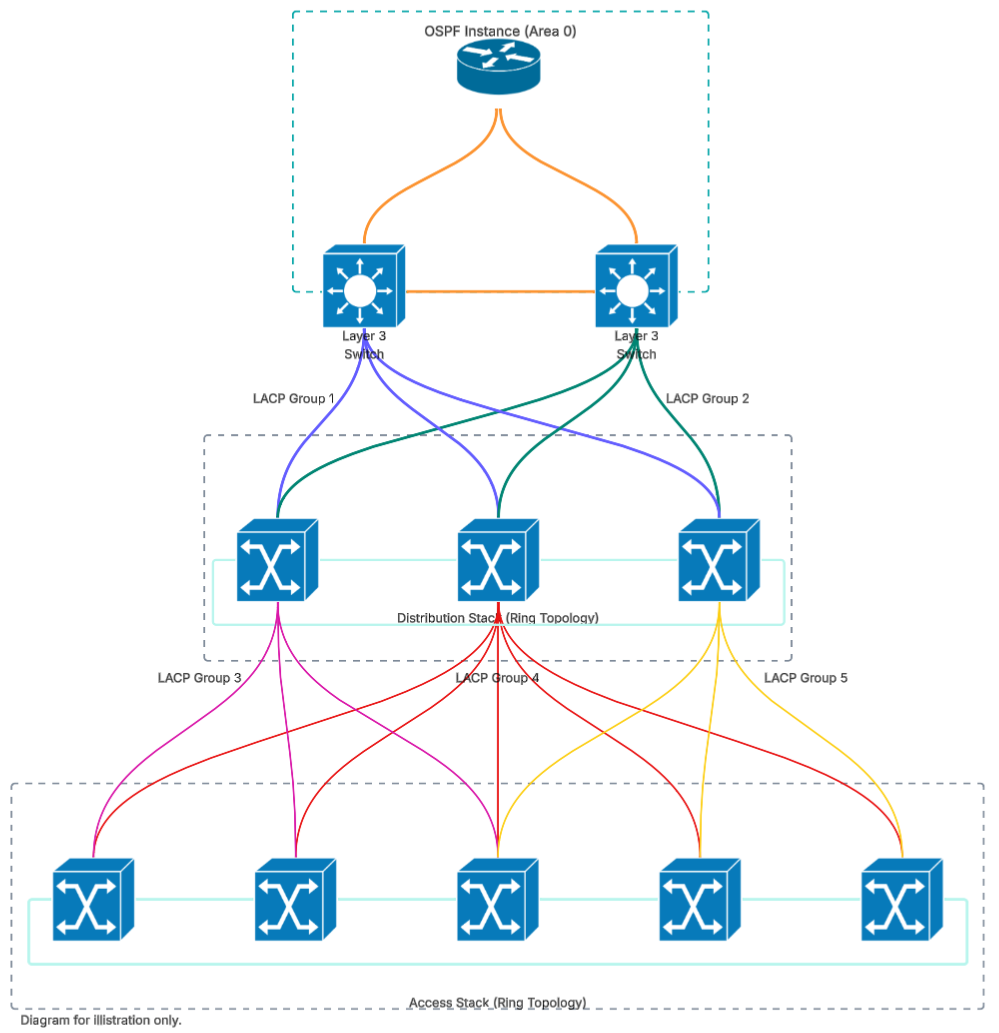
First is Link Aggregation Control Protocol (LACP – IEEE 802.3ad), which allows us to bond multiple uplinks between the core and routers, distribution, or access switches. If one link fails, traffic continues to flow through the remaining active members of the LACP group. Think of it like adding lanes to a motorway: if lane one gets blocked, lanes two and three keep traffic moving. There might be more congestion, but everything still flows.
Secondly, depending on hardware and budget, we can introduce first hop redundancy protocols like VRRP and HSRP. These protocols enable Layer 3 switches or routers to share a virtual IP address. If the active device fails, the backup device takes over the routing role and the shared virtual IP address automatically.
(Personal note: I always aim to mirror the configuration on each core switch as closely as operationally possible. This becomes especially important when using VRRP or HSRP, as neither of these protocols provides full device-level high availability. They only handle gateway redundancy. If you're forced to fail over, having consistent configs helps avoid unexpected behaviours.)
Alternatively, or in combination, we might employ dynamic routing protocols such as Open Shortest Path First (OSPF) or Enhanced Interior Gateway Routing Protocol (EIGRP) if you are in a Cisco environment. Operating at layer 3, these protocols make intelligent decisions based on link speed, distance and path cost to determine the best route for traffic.
These intelligent protocols come with a major bonus they self-heal. If a link goes down, its neighbours can adjust in real time, working out the best path based on live data and minimising any disruption to business-as-usual operations.
Distribution
Next down the food chain is distribution. This layer is often easier to build and design for redundancy, utilising a wide range of options from physical and technological standpoints.
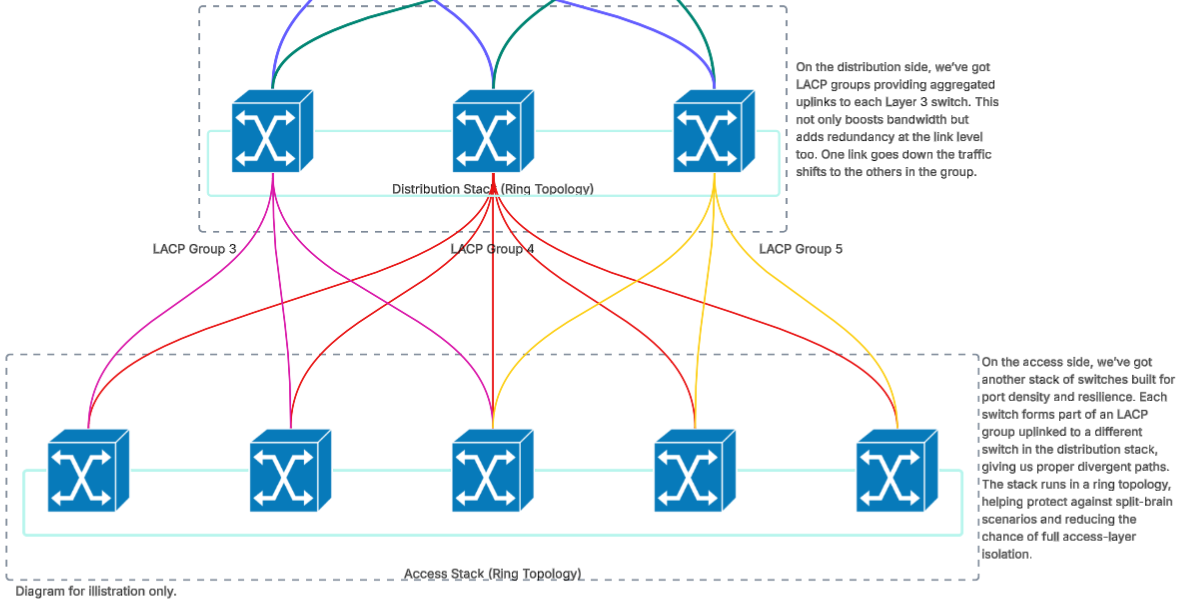
Physically, it’s not uncommon to find switch stacking at this level. This allows for multiple switches to act as a single logical unit in either a ring or chain topology. I would always advocate for a ring for improved redundancy and increased bandwidth.
One of the major benefits of stacking is that we can distribute your LACP groups throughout the entire stack, so you’re not reliant on one switch. I liken switches to buildings and a standalone switch is a bungalow. A stacked switch is like a high-rise with multiple floors, high-speed lifts and built-in redundancy. I couple stacking with LACP uplinks to both access and core to take advantage of the improved bandwidth and redundancy.
If stacking is not an option, we can use Multi-chassis Link Aggregation Group (MLAG/MC-LAG). MLAG allows two or more switches to share a single LAG endpoint. If a switch in MLAG group were to fail it would be able to continue load-balancing across the remaining active LACP members. The caveat here is that most MLAG implementations are tied to the manufacturer.
On top of this I’ll usually introduce a modern variation of the Spanning Tree Protocol (STP). The original IEEE standard 802.1D paved the way, but I rarely use it anymore as it is too slow for our networks today
STP helps reduce layer two loops, which can lead to broadcast storms bringing the network and business to a grinding halt. often by an unsuspecting employee plugging in both ends of a patch lead, or a technician mispatching during maintenance. STP isn’t perfect and many of us consider it a necessary evil, but it remains a vital part of network design.
Access
The last layer in our networks, in my opinion, just as important as the edge. Its what keeps our endpoints connected, access points broadcasting and our VoIP handsets ringing.
This is the sticking point for network redundancy as the issue is obvious but the solution far from it. One point of failure: the access switch.
Yes it’s common to find stacking at this layer to improve bandwidth and redundancy, LACP, MLAG, and MSTP (Multiple Spanning Tree Protocol). The real issue appears at the endpoint, almost all client devices have just one network port. Could we have PCs with dual network cards that go to two different switches in the stack or different network cabs\IDF’s? Technically yes. But is this really feasible? No for 99.9% of organisations, absolutely not.
So what are my solutions? I typically have two.
Option 1: Install two network points at each desk. Not only does this support additional devices such as VoIP phones, but it gives us the option to uplink into a completely different switch or a completely separate cabinet, provided the structured cabling has been designed with divergence in mind. In the event of a failure, the user or technician can simply move the patch lead to the second socket. It’s simple and doable for most staff but requires forward thinking and an eye for detail during the design phase.
Option 2: Keep a spare switch (or two, because when it rains it pours) on standby in case of failure. It might sit gathering dust hopefully you’ll never need it, but when you do, it saves a major headache and keeps business downtime to a minimum.
Redundancy at the access layer is far from perfect, and as technicians we have to accept that. It’s a key point I always highlight to clients and talk them through. When they can see the risk through my eyes, they’re able to make informed decisions that fits the needs and priorities of their business.
Compact Networks should get TLC too
I concede so far this post has been technical focused on mid to large size networks, however I cut my teeth on the smaller ones, and I wear the battle scars proudly.
A compact setup can absolutely follow the same principles and best practices to build network that has elements of resilience and performance, even with limited kit. I’ve always approached these networks with a simple mindset “Out the box what can I do with the equipment I’ve got?”
Most entry-level routers and managed switches support LACP though it’s always worth double-checking what your gear is capable of (you might be pleasantly surprised). If I had two switches, I’d build an LACP group between them using ports at either end to create some basic redundancy.
STP (Spanning Tree Protocol) has been around for years, in a single switch setup I always like to turn it on it’s a low-risk set and forget failsafe. It prevents any accidental loops, which can and do happen ask any IT technician, It’s always someone patching both ends of a cable into the same switch and it always happens on a Friday at 16:30.
Then there’s design. One mistake I see, often (by both IT techs and DIYers) is two or more switches daisy-chained together, where one relies on the other to reach the rest of the network. That’s a risk. Instead uplink them directly into the router. It’s a small but effective way to eliminate the risk of the piggy-in-the middle failure point.
These wins only cost time not money. They can however save a business a lot of pain.
At the end of the network
It doesn't matter if your network spreads throughout continents or a cabinet. It still starts with planning. If I haven’t made it clear already: with redundancy, you don’t need a blank cheque. It’s about using what you need and have in a smart, intuitive way. From core to access to compact networks, every part of the infrastructure deserves attention.
When the network goes down, everything else follows. Invest in the boring stuff, it’s what keeps the shiny stuff running.